 Screenshot of the training environment.
Screenshot of the training environment.Intro
The code in this repository implements processes to train and execute autonomous agents that can navigate in a BananaBrain unity environment. The enviroment download information can be found in the provided repository.
Environment
The simulation contains a single agent that navigates a large environment. At each time step, it has four actions at its disposal:
0- walk forward1- walk backward2- turn left3- turn right
The state space has 37 dimensions and contains the agent’s velocity, along with ray-based perception of objects around agent’s forward direction. A reward of +1 is provided for collecting a yellow banana, and a reward of -1 is provided for collecting a blue banana.
The task is episodic, and in order to solve the environment, your agent must get an average score of +13 over 100 consecutive episodes.
Solution
In this repo, you can find the code to train and run AI trained though Deep Reinforcement Learning based on the DQN Architecture. In particular, You’ll find implementation of the following variants:
- Basic Agent (for execution only)
Agent - Double DQN with Classic Memory Replay
ReplayDDQNAgent - Double DQN with Priority Based Memory Replay
PriorityReplayDDQNAgent
Each those support both the following architectures:
- DQN
DQN - Dueling DQN
Dueling_DQN
The problem we are solving in this repo is the BananaBrain Game implemented as a Unity virtual environment.
The game consists in collecting as many yellow bananas as possible, while avoiding the blue bananas.
For each yellow banana collected the overall score increases by +1, while collecting a blue banana will provide a -2 score decrease and will terminate the game episode.
The problem will be considered solved once the agent can get an average score over 100 episodes of 13 in less than 1800 episodes. However, since, as you will see in the Report.md, that goal is reached very early (episode 400-700) we’ll push the training to a max number of episodes and we will save the agent version that performed the best on that metric. The winning agent will be referred as trained_model.pth in the asset folder.
DQN
The main Idea behind Q-learning is that if we have a function $Q*: State \times Action \rightarrow \mathbb{R}$ telling us the expected return of each state-action tuple we can construct a policy that behaves selecting the best action while being in a certain state. $$\pi^{*}(s) = \arg \max_{a} Q^{*}(s, a)$$ In DQN, we train a neural network to estimate Q^{*}. We do so through the Bellman-Equation updates: $$Q^{\pi}(s, a)= r + \gamma Q^{\pi}(s', \pi(s'))$$ We try to obtain the optimal $Q^{*}$ function by minimizing $\delta = Q(s, a) - (r + \gamma \max_{a}Q(s', \pi(s')))$ using MSE, MAE or The Huber Loss.
Results
he Final approach used all the above mentioned mechanisms reaching a final average score superior to 15. Here are reported an animated GIF captured during the training process and the plot of the average score (100 episodes) during each episode: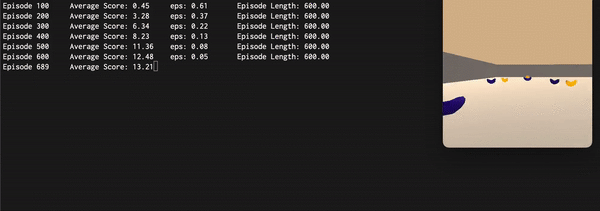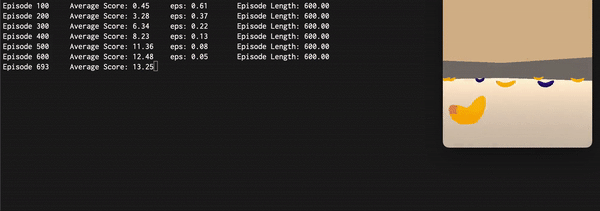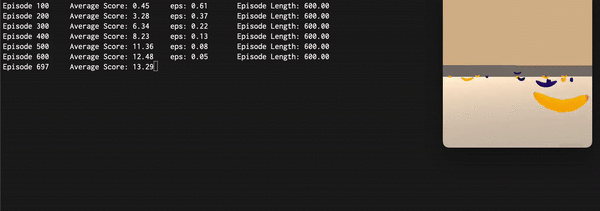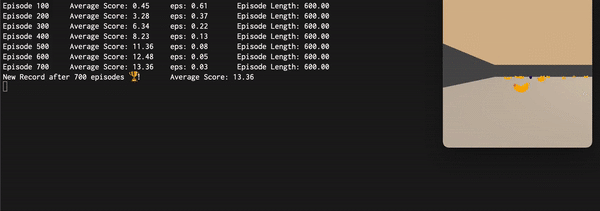

Here we can see an example run of the agent:
Claudio Coppola
Robotics And Machine Learning Scientist
Machine learning and robotics expert with experience in industry and academia applying AI and data science to transportation forecasting, manufacturing automation, robotic perception, and human-robot interaction.